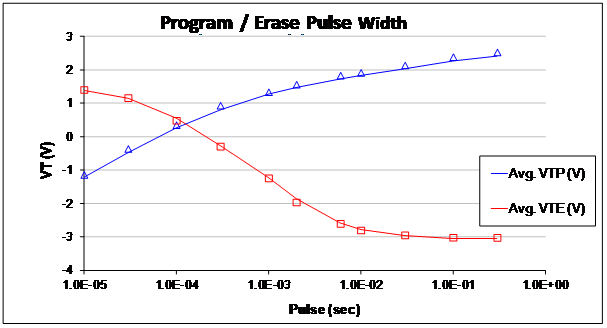
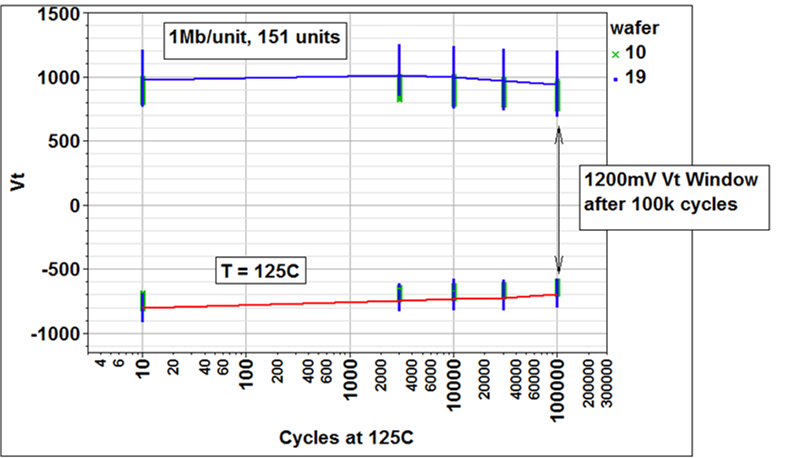
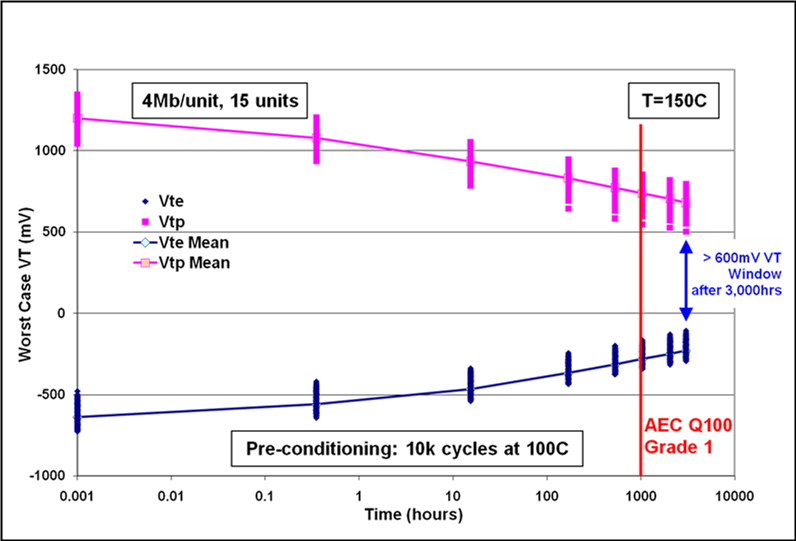
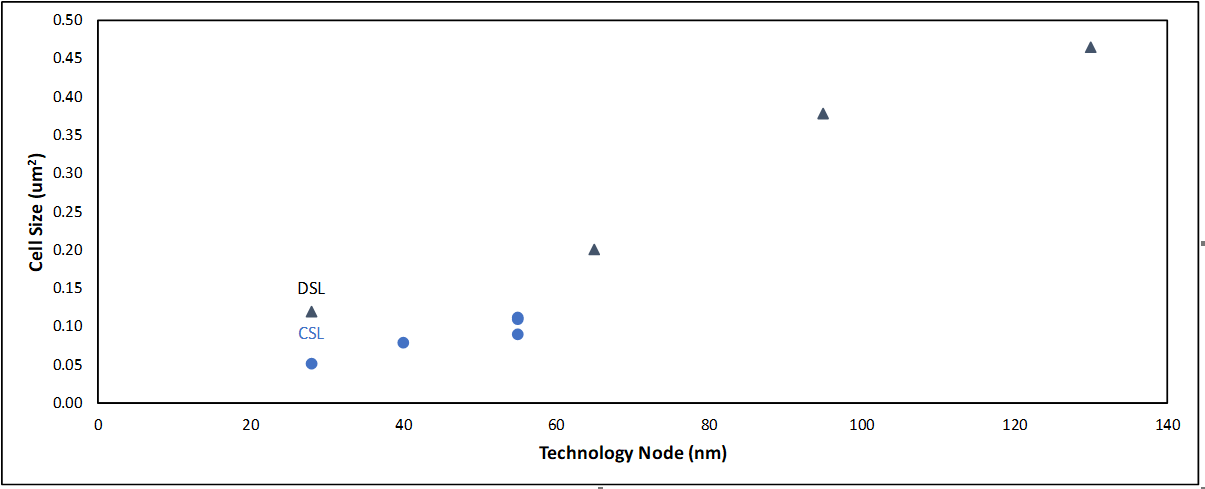
PAUL STOCKMAN, Head of Market Development, Linde Electronics, Taipei, Taiwan
Nearly 60 years after Richard Feynman delivered his celebrated talk, which became the foundation for nanotechnology [1], many of the milestones he envisioned have been achieved and surpassed. In particular, he discussed computing devices with wires 10 to 100 atoms in width. Today we are reaching the smaller end of that range for high-volume FinFET and 10nm class DRAM chips, and device manufacturers are confidently laying the roadmaps for generations of conductors with single atom scales.
While device shrinkage has continued apace, it has not been without consequences. As chip circuit dimensions dip into the atomic range, bulk semiconductor properties which allowed for relatively simple scaling are breaking down and atomic-level physics are beginning to dominate. At this scale, every atom counts. And when different isotopes of the needed atoms have significantly different properties, the ability to create isotopically pure materials (IPMs) becomes essential.
In this paper, we begin by discussing several examples of IPMs used in current high-volume electronics manufacturing: the physics at play and the materials selected. With the near future in focus, we then look at coming applications which may also require IPMs. Finally, we look at the current supply of IPM precursors, and how this needs to be developed in the future.
What is an isotope?
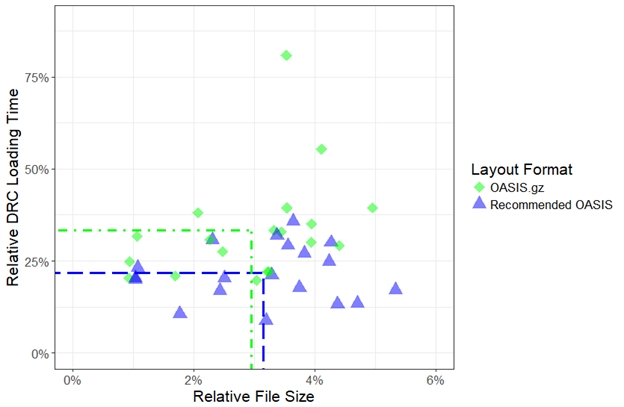
Isotopes are atoms of a particular element which have the same number of protons in their nucleus, but different numbers of neutrons (FIGURE 1). The number of protons determines which element the atom is: hydrogen has one proton, helium has two protons, and so on in the ordering used for the periodic table.
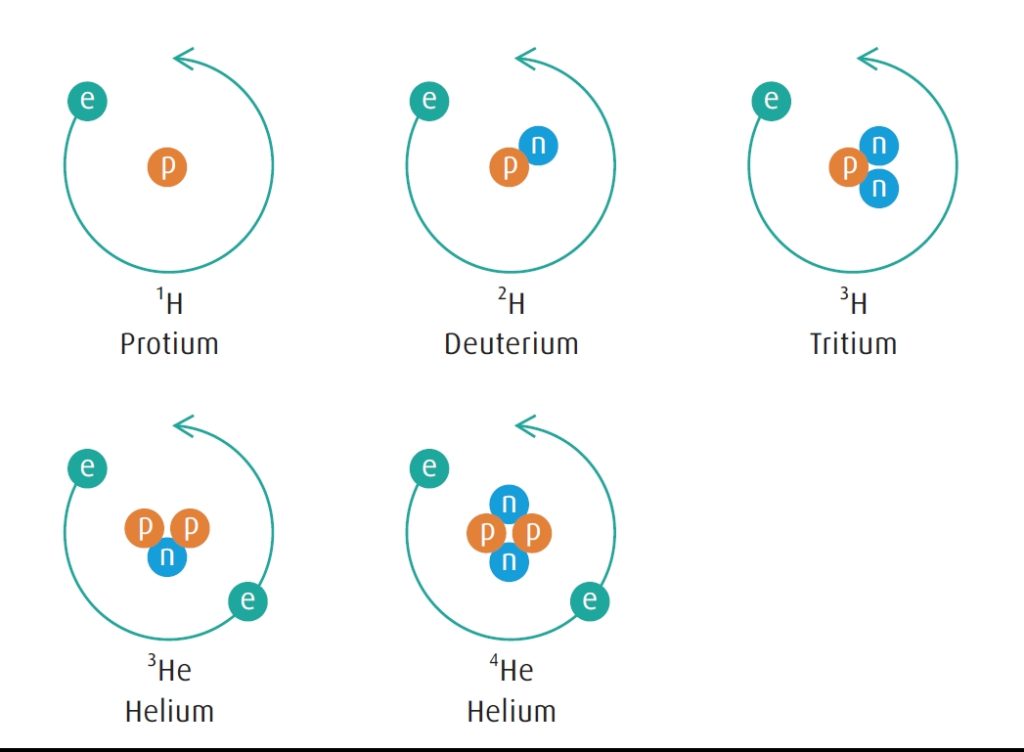
FIGURE 1. The stable isotopes of hydrogen and helium. The number of protons determines the element, and the number of neutrons determines the isotope. The superscript number is the sum of the protons and the neutrons.
Different isotopes of the same element all have nearly exact chemical behavior – that is how they form and break molecular bonds in chemical reactions – but sometimes exhibit significantly different physical behavior. It is these differences in physical behavior which become important when electronics are made on the atomic scale.
For the purposes of engineering semiconductors, it is important to consider two different classes of isotopes.
- Radioactive: The nuclei of these of these isotopes are unstable, break apart into different and lighter elements, and often emit radiation in the form of alpha particles or light. The rate at which this happens can be quite fast – much less than a nanosecond – to longer than a billion years for half of the material to undergo decay. It is this type of isotope which was first historically observed and which we often first learn about. The element uranium has five different isotopes which naturally occur on earth, but all of these are radioactive.
- Stable: All other isotopes are termed stable. This means that they have not been observed to break apart, even once, when looking at bulk quantities of material with many billions of atoms. We do have evidence that some of these isotopes, termed primordial, are indeed stable over the span of knowable time, as we have evidence that they have formed and not decayed since the formation of the universe.
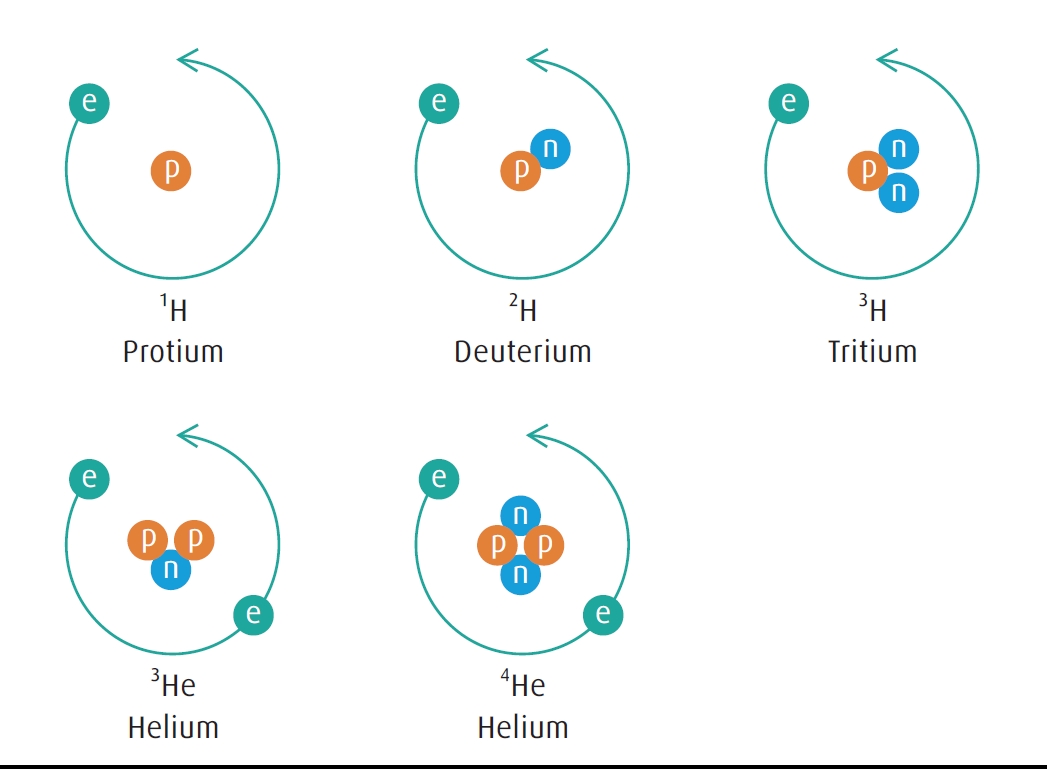
For the use of IPMs to engineer semiconductors, only stable isotopes are considered. Even for radioactive isotopes which decay slowly, the fact that current logic and memory chips have more than a billion transistors means that one or more circuits have the likelihood to be corrupted over the useful lifetime of the chip. In FIGURE 2, we show some common elements used in semiconductor manufacturing with their stable isotopes and naturally occurring abundances.
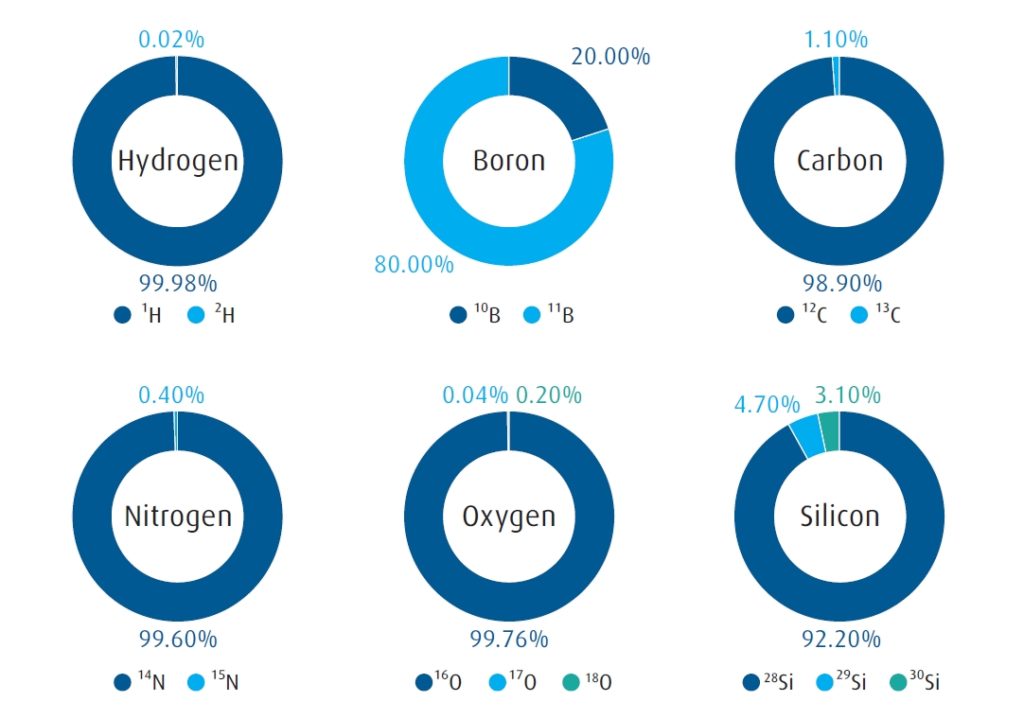
FIGURE 2. The natural abundance of stable isotopes for elements most relevant for electronics devices.
Current applications
There are already several electronics applications for IPMs, which have been used in high volume for more than a decade.
Deuterium (D2 = 2H2): Deuterium (D) is the second stable isotope of hydrogen, with one proton and one neutron. As a material, it is most commonly used in electronics manufacturing as the IPM precursor gas D2. Chemically, deuterium can be substituted directly for any reaction using normally abundant hydrogen. Deuterium is made by the electrolysis of D2O, often called heavy water, which has been already enriched in the deuterium isotope.
Important physical property — mass: For most elements, the difference in mass among their isotopes is only a few percent. However, for the lightest element hydrogen, there is a two-fold difference in mass. The chemical bond between a hydrogen atom and a heavier bulk material can be roughly approximated by the simple classical mechanics example of a weight at the end of the spring. When the weight is doubled, the force on the spring is also doubled (FIGURE 3).
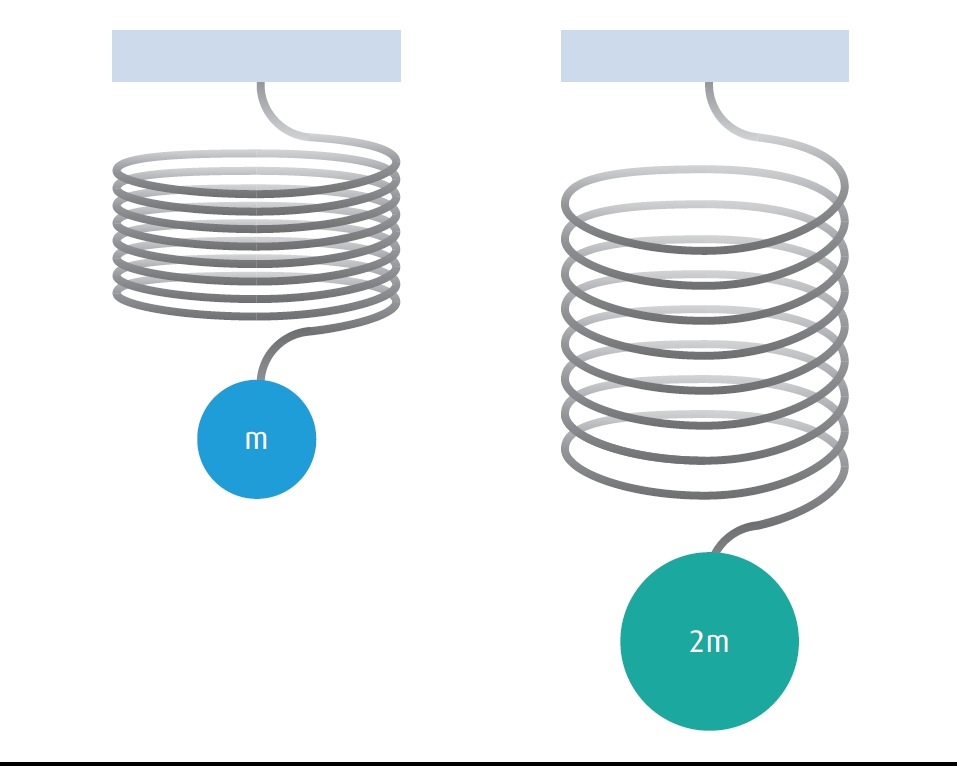
FIGURE 3. According to Hooke’s Law, a spring will stretch twice as far when attached to a mass twice the original. When the balls and springs are bonds to naturally abundant hydrogen 1H and deuterium 2H, they vibrate at different frequencies.
At the atomic level, quantum mechanics applies, and only certain amounts of energy, or quanta, can excite the spring. When deuterium 2H is substituted for the much more abundant 1H, the amount of energy which can excite the spring changes by almost 50%.
Long-distance optical fibers: Optical fibers, like semiconductors, rely on silicon oxide as a primary material. The fiber acts as a waveguide to contain and transmit bursts of near-infrared lasers along the length of the fiber. The surface of the silicon oxide fiber is covered with hydroxide (oxygen-hydrogen), which is formed during the manufacture of the fiber. Unfortunately, the hydroxide chemical bonds absorb small amounts of the laser light with every single reflection against the surface, which in turn diminishes the signal. By substituting deuterium 2H for normally abundant hydrogen 1H on the surface hydroxide, the hydroxide molecular spring no longer absorbs light at the frequencies used for communication.
Hot carrier effect between gate and channel: As transistor sizes decrease, the local electric fields inside transistors increase. When the local field is high enough, it can generate free electrons with high kinetic energy, known as hot carriers. Gate oxides are often annealed in hydrogen to reduce the deleterious effects of these hot carriers. But the hydride bonds themselves can become points of failure because the hot carriers have just the right amount of energy to excite and even break the hydride bonds. Just like in the optical fiber application, substituting deuterium 2H for naturally abundant 1H changes the energy of the bond and protects it against hot carrier damage. The lifetimes of the devices are extended by a factor of 50 to 100.
11-Boron trifluoride (11BF3): Boron has two naturally occurring stable isotopes 10B at 20% and 11B at 80%. Boron is used in electronics manufacturing as a dopant for silicon to modify its semiconducting properties, and is most commonly supplied as the gases boron trifluoride (BF3) or diborane (B2H6). 11BF3 is produced by the distillation of naturally abundant BF3, and can be converted to other boron compounds like B2H6.
Important physical property – neutron capture: The earth is continuously bombarded by high-energy cosmic radiation, which is produced primarily by events distant from our solar system. We are shielded from most of this radiation because it reacts with the molecules in our outer atmosphere. A by-product of this shielding mechanism are neutrons which constantly shower the earth’s surface, but are not strong enough to pose any biological risk, usually passing through most materials without reaction. However, the nucleus of the 10B atom is more than 1 million times likely to react with background neutrons versus other isotopes, including 11B. This results in splitting the 10B atom into a 7Li (lithium) atom and an alpha particle (helium nucleus) (FIGURE 4).
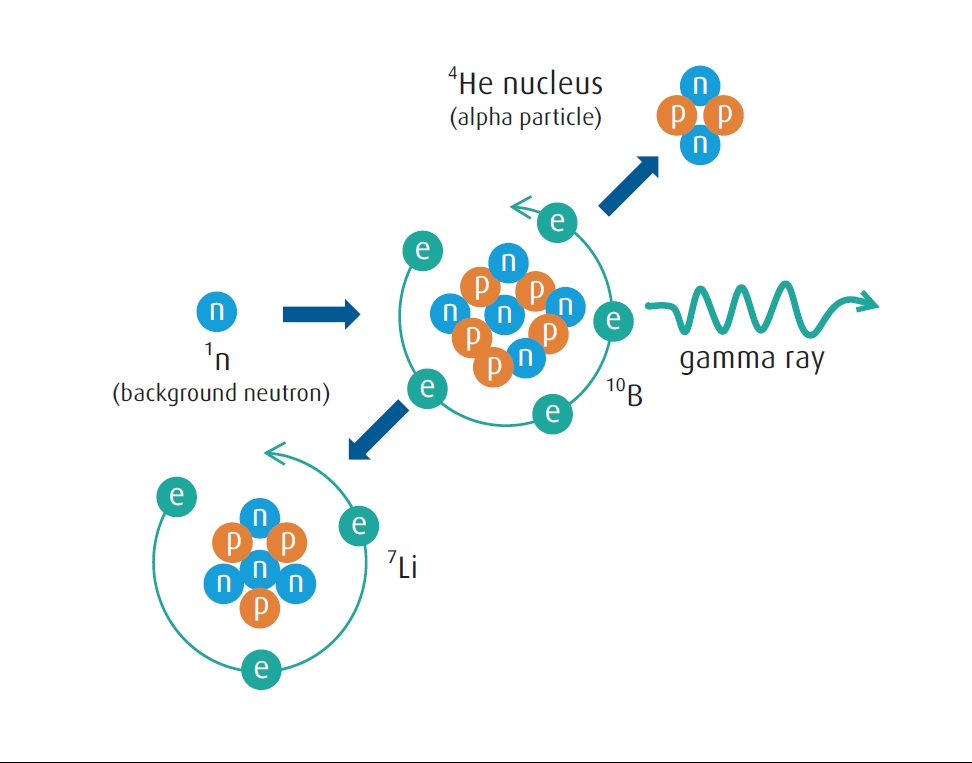
FIGURE 4. 10B neutron capture. When a 10B atom captures a background neutron, it breaks into a smaller 7Li atom and emits alpha and gamma radiation.
The smallest semiconductor gates now contain fewer than 100 dopant boron atoms. If even one of these is transmuted into a lithium atom, it can change the gate voltage and therefore the function of the transistor. Furthermore, the energetic alpha particle can cause additional damage. By using BF3 which is depleted of 10B below 0.1%, semiconductor manufacturers can greatly reduce the risk for component failure.
Initially, IPMs D2 and 11BF3 were used for making chips with the most critical value, like high performance computing processors, or remote operating environments like satellites and space vehicles. Now, as chip dimensions shrink to single nanometers and transistors multiply into the billions, these IPMs are increasingly being adopted into more high volume manufacturing processes.
Developing and future applications
As devices continue to scale to atomic dimensions and new device structures are developed to continue the progression of electronics advance, IPMs will play a greater role in a future where every atom counts. We present in this section a few of the nearest and most promising applications.
Important physical property – thermal conductivity: Thermal conductivity is the property of materials to transfer heat, which is especially important in semiconductor chips where localized transistor temperatures can exceed 150 C and can affect the chip performance. Materials like carbon (either diamond or graphene) and copper have relatively high thermal conductivity; silicon and silicon nitride medium; and oxides like silicon oxide and aluminum oxide are much lower. However, with all of the other design constraints and requirements, semiconductor engineers seldom choose materials to optimize thermal conductivity.
When viewed in classical mechanics, thermal conductivity is like a large set of balls and springs. In an atomically pure material like diamond or silicon, all the springs are the same, and all the balls are nearly the same – the differences being the different masses of the naturally occurring isotopes. When IPMs are used to make to make the material, all the balls are now exactly the same, there is less disorder, and heat is transferred through the matrix of balls and springs more efficiently. This has been demonstrated in graphene to improve the thermal conductivity at room temperature by 60% (Figure 5), and other studies have shown a similar magnitude improvement in silicon.
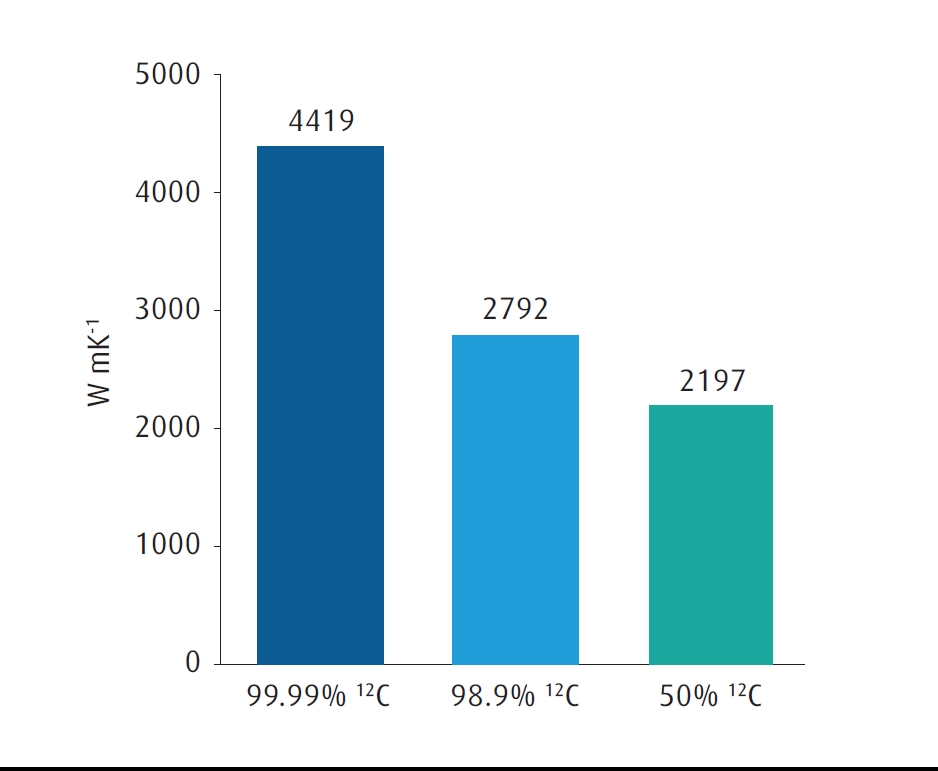
FIGURE 5. Thermal conductivity of graphene for different concentrations of 12C content. 99.99% 12C is achievable using commercial grade 12CH4 methane; 98.6% 12C is the value of naturally abundant carbon on earth; 50% 12C is an artificial mixture to demonstrate the trend. Source: Thermal conductivity of isotopically modified graphene. S Chen et al., Nature Materials volume 11, pages 203–207 (2012).
Silicon epilayers: Epitaxially grown silicon is often the starting substrate for CMOS manufacturing. This may be especially beneficial for HD-SOI applications where trade-offs of substrate cost vs processing cost and device performance are already part of the value equation.
Sub 3nm 2D graphene FETs: Graphene is a much-discussed material being considered for sub-3nm devices as the successor technology for logic circuits after the FinFET era. Isotopically pure graphene could reduce localized heating at the source.
Important physical property – nuclear spin: Each atomic nucleus has a quantum mechanical property associated with it called nuclear spin. Because it is a quantum mechanical property, nuclear spin is measured in discrete amounts, and in this case half-integer numbers. Nuclear spin is determined by the number of protons and neutrons. Since different isotopes have different numbers of neutrons, they also have different nuclear spin. An atomically and isotopically pure material will have atoms with all the same spin.
Qubits and quantum computing: Much research has been published recently about quantum computing as the successor to transistor-based processors. IBM and Intel, among others, have made demonstration devices, albeit not large enough for practical applications yet. The most promising near-term realization of quantum computing uses qubits – atomic two-state components—which store and transmit information via electron spin, which is a property analogous to nuclear spin, and can be affected by nuclear spin. Many of these early devices have been made with isotopically pure diamond (carbon) or silicon matrices to avoid disorder from having multiple values of nuclear spin in these devices.
12-Methane (12CH4): Carbon is predominantly 12C, with about 1.1% 13C in natural abundance. A large demand already exists for 13C chemicals, primarily used as markers in studying chemical and biological reactions. 13C is produced primarily by the distillation of carbon monoxide (CO), and then chemically converted to other carbon-containing precursors like methane (CH4). At the same time 13C is produced, a large amount of 13C-depleted 12CO is produced, which serves as a less expensive feedstock for applications which require IPMs made from carbon.
28-Silane (28SiH4) and other silicon precursors: There are no such large applications driving the production of isotopically pure silicon precursors yet. Currently, research quantities of silicon tetrafluoride (SiF4) are produced primarily by using gas centrifuges, and then converted into silicon precursors like silicon tetrachloride (SiCl4), trichlorosilane (SiHCl3), dichlorosilane (SiH2Cl2), and silane (SiH4). Distillation of one or more of these materials would be a less expensive option for larger-scale production.
Other IPM precursors already exist for oxygen and nitrogen compounds, and are relatively inexpensive because they are also by-products from the production of chemical markers for less abundant isotopes. Aluminum and phosphorous only have one stable isotope, and so all compounds produced with these are isotopically pure in these elements.
Production methods
Production of IPMs is challenging because of the limited differences in physical and chemical properties normally used to separate and purify materials, and because of the low concentration of some of the desired isotopes. A number of creative approaches have been applied, and often the methods are repeated to obtain the desired enrichment and purity of the IPM. We give a description here of the two methods used today in the production of IPMs relevant to the electronics industry. Importantly, all of these require gas-phase starting materials in order to enhance the physical differences that do exist among the isotopes.
Distillation: The more familiar of the two is distillation, which relies on differing boiling points of materials to separate them into lower boiling point fractions called lights (which often are lighter in mass) and higher boiling point fractions which are called heavies. Because the boiling point differences are a fraction of a degree, very long distillation columns are used. Distillation is best used with lighter compounds, and is the preferred method for producing D2O, 11BF3, 12CO / 13CO, and isotopes of nitrogen and oxygen (FIGURE 6).
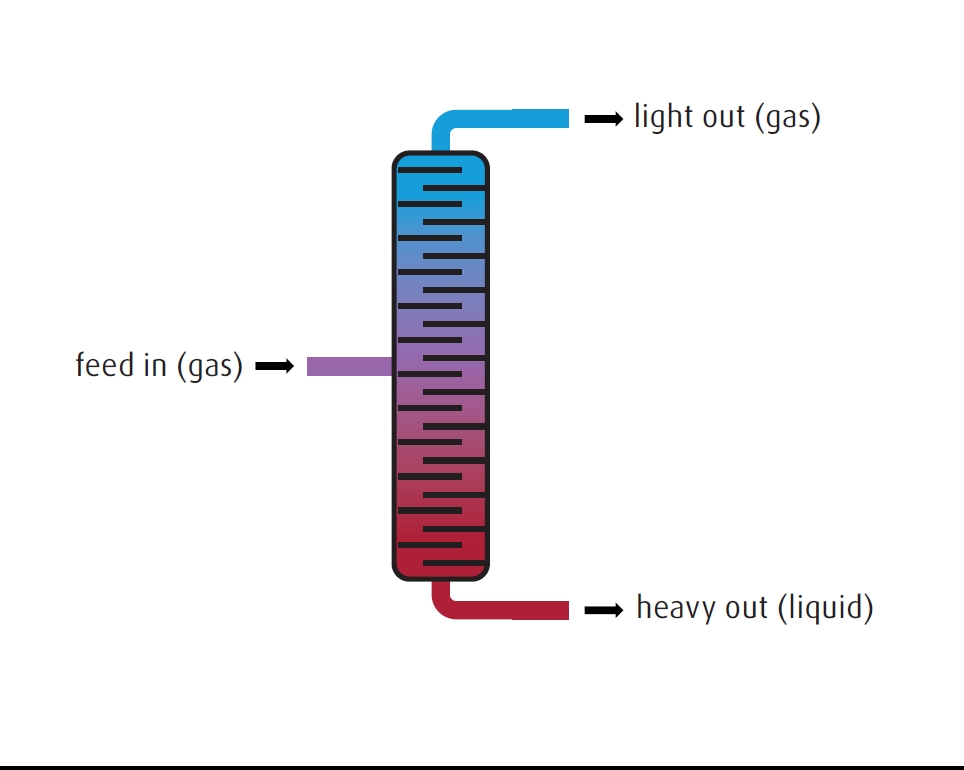
FIGURE 6. Isotope separation. Distillation. Gas is fed into the middle of the distillation column. By the process of condensation and boiling on many plates, the lighter isotope is separated as a gas leaving the top of the column, and the heavier isotope leaves as a liquid at the bottom.Centrifuge: After a number of other methods were tried, gas centrifuges were the method ultimately chosen to scale the separation of the 235U uranium isotope in uranium hexafluoride (UF6) gas used for the first atomic devices during the Manhattan Project, and remains the preferred method of obtaining this useful isotope and other isotopes of heavier elements. The gas is spun at very high speeds – around 100,000 rpm – and the higher mass isotopes tend toward the outer regions of the centrifuge. Many gas centrifuges are linked in arrays to achieve the desired level of enrichment. Currently, useful quantities of of 28SiF4 and 30SiF4 are produced with this method (FIGURE 7).
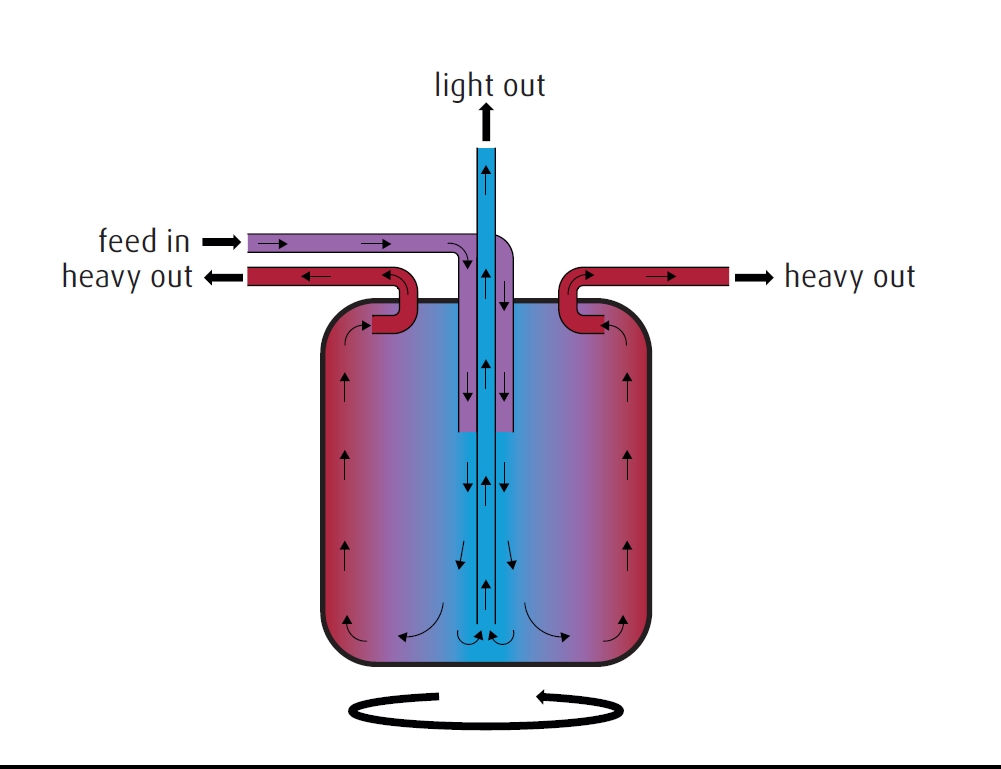
FIGURE 7. In this isotope separation centrifuge, gas is fed into the center of the centrifuge, which is spinning at a very high rate of 100,000 rpm. The heavier isotope is thrown to the sides, while the lighter isotope remains in the center.
Conclusion
In the hundred-year anniversary of Richard Feynman’s birth, we are still finding plenty of room at the bottom. But as we go further down, we must look more carefully at what is there. Increasingly, we are seeing that individual atoms hold the properties that are important today and which will support the developments of a not-too-distant tomorrow. IPMs are an important part of creating that reality.
Linde Electronics is the leader in the production of IPMs which are important to electronics today, and holds the technology to produce the IPMs which will support the development of tomorrow’s devices. Linde has made recent investments for the production of deuterium (D2) and 11BF3 to satisfy global electronics demand, and has a long history in the production, purification, and chemical synthesis of stable isotopes relevant to semiconductor manufacturing.
Reference
- Feynman, Richard P. (1960) There’s Plenty of Room at the Bottom. Engineering and Science, 23 (5). pp. 22-36.