
DENNIS JOSEPH, Mentor, a Siemens Business, Beaverton, OR
As foundries advance their process technology, integrated circuit (IC) layout designers have the ability to deliver more functionality in the same chip area. As more content goes into a layout, the file size also increases. The results? Design companies are now dealing with full-chip Graphic Database System (GDSII/GDS™) layouts that are hundreds of gigabytes, or even terabytes, in size. Although additional storage can be purchased relatively inexpensively, storage availability is becoming an ongoing and increasingly larger concern.
And storage is not the only, or even the most important, issue. File size and layout loading time become increasingly critical concerns as process technology advances. Electronic design automation (EDA) tools can struggle to effectively manage these larger layouts, resulting in longer loading times that can frustrate users and impact aggressive tape-out schedules. Layout loading happens repeatedly throughout the design process—every time designers create or modify a layout, check timing, run simulations, run physical verification, or even just view a layout—so the effect of loading time becomes cumulative throughout the design and verification flow.
Layout designers often try to address the file size problem by zipping their GDS layouts. This approach does reduce file sizes, but it can actually increase loading times, as tools must unzip the file before they can access the data. Need a better, more permanent, solution?
Switch to the Open Artwork System Interchange Standard (OASIS®) format, which can reduce both file sizes and loading times. The OASIS format has been available for almost 15 years [1] and is accepted by every major foundry. It is also supported by all industry standard EDA tools [2].
The OASIS format has several features that help reduce file size compared to the GDS format.
- OASIS data represents numerical values with variable byte lengths, whereas the GDS format uses fixed byte lengths.
- OASIS functionality can also recognize complex patterns within a layout and store them as repetitions, rather than as individual instances or geometry objects.
- The OASIS CBLOCKs feature applies Gzip compression to the individual cells within a layout. Because this compression is internal to the file, tools do not need to create a temporary uncompressed file, which is often necessary with normal Gzip compression. Additionally, although unzipping a Gzip file is typically a single-threaded process, CBLOCKs can be uncompressed in parallel.
- Strict mode OASIS layouts contain an internal lookup table that can tell a reader the location of different cells within the file. This information allows the reader to more efficiently parallelize the loading of the layout and can offer significant loading time improvement.
Although features such as CBLOCK compression and strict mode are not required, it is highly recommended that layout designers utilize both to realize the fastest loading times in their tools while maintaining small file sizes.
What’s wrong with gds.gz?
Many layout designers have resorted to zipping their GDS layouts, which in measured testcases reduced file sizes by an average of 85%. However, beyond cell placements, designs typically contain a lot of repetition that is not recognized by the GDS format. As a result, much of a GDS file is redundant information, which is why zipping a GDS layout can achieve such significant compression ratios. The OASIS format natively recognizes this repetition and stores this information more compactly. Additionally, taking advantage of CBLOCKs reduced file sizes by an additional 80% from the zipped GDS layouts and by almost 97% from the uncompressed GDS layouts. FIGURE 1 shows the file size reduction that can be achieved by using the OASIS format instead of a zipped GDS layout.
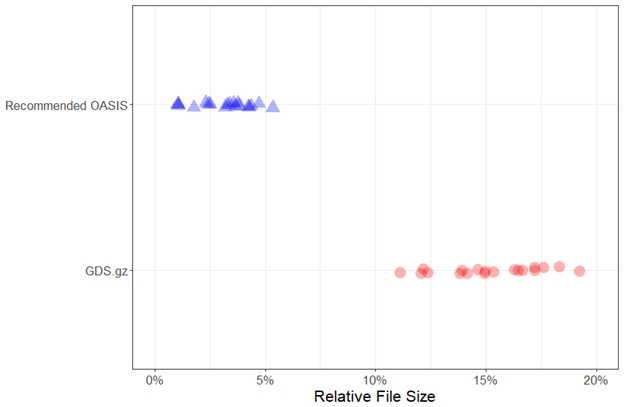
FIGURE 1. File sizes relative to the uncompressed GDS layout (smaller is better). In all measured testcases, the recommended OASIS options delivered smaller file sizes than zipping the uncompressed GDS layout.
In addition, a zipped GDS layout’s file size reductions are usually offset by longer loading times, as tools must first unzip the layout. As seen in FIGURE 2, the DRC tool took, on average, 25% longer to load the zipped GDS layout than the corresponding uncompressed GDS layout. Not only were the corresponding recommended OASIS layouts smaller, the DRC tool was able to load them faster than the uncompressed GDS layouts in all measured testcases, with improvements ranging from 65% to over 90%.
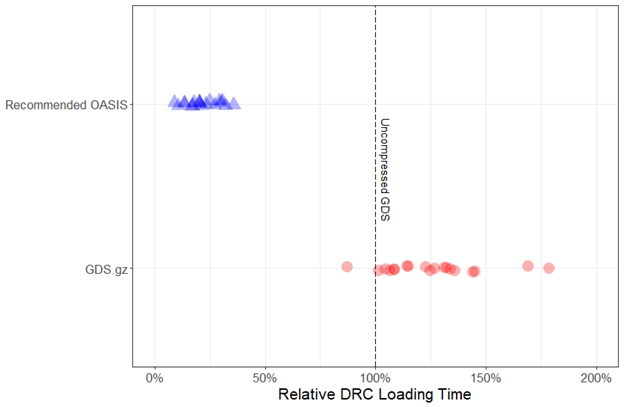
FIGURE 2. DRC loading times relative to the uncompressed GDS layout (smaller is better). In all measured testcases, the recommended OASIS options delivered faster DRC loading times than zipping the uncompressed GDS layout.
While Figs. 1 and 2 considered file sizes and loading times separately, the reality is that layout designers must deal with both together. As seen in FIGURE 3, plotting both quantities on the same chart makes it even clearer that the recommended OASIS options deliver significant benefits in terms of both file size and loading time.
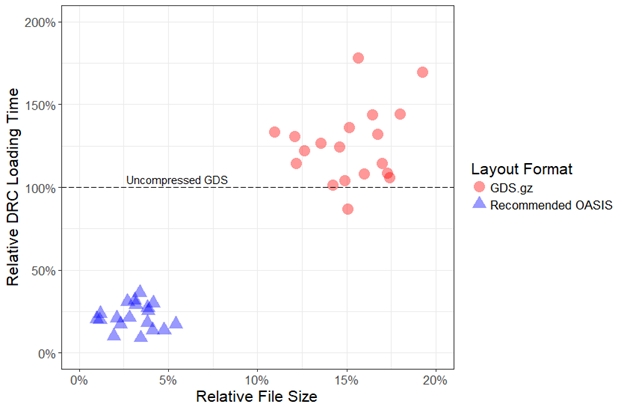
FIGURE 3. DRC loading times versus file size, both relative to the uncompressed GDS layout (smaller is better for both axes). In all measured testcases, the recommended OASIS options delivered faster DRC loading times and smaller file sizes than zipping the uncompressed GDS layout.
Loading time costs are incurred throughout the design process every time a user runs physical verification or even just views a layout. DRC tools are typically run in batch mode, where slow loading performance may not be as readily apparent. However, when viewing a layout, users must actively wait for the layout to load, which can be very frustrating. As seen in FIGURE 4, viewing a zipped GDS layout took up to 30% longer than viewing the uncompressed GDS layout. In addition to the file size reduction of almost 80% (compared to the zipped GDS layout), switching to the OASIS format with the recommended options reduced the loading time in the layout viewer by an average of over 70%.
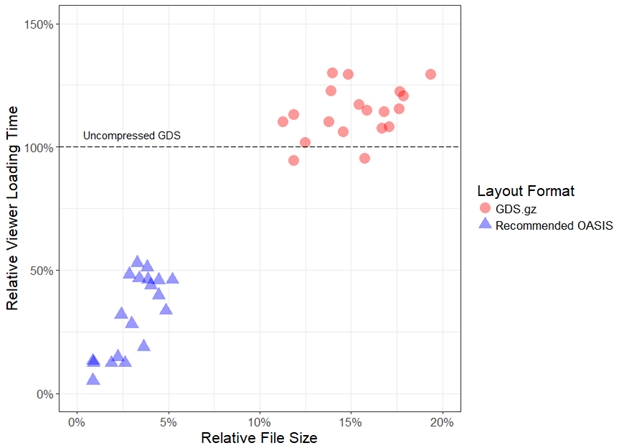
FIGURE 4. Layout viewer loading times versus file size, both relative to the uncompressed GDS layout (smaller is better for both axes). In all measured testcases, the recommended OASIS options also delivered faster loading times than zipping the uncompressed GDS layout.
What about zipping an OASIS layout?
Layout designers may think that zipping an OASIS layout can provide additional file size reductions. However, CBLOCKs and Gzip use similar compression algorithms, so using both compression methods typically provides only minimal file size reductions, while loading times actually increase because tools must uncompress the same file twice.
In a few cases, zipping an uncompressed OASIS layout may reduce file sizes more than using CBLOCKs. However, layout readers cannot load a zipped OASIS layout in parallel without first unzipping the file, which leads to increased loading times. As seen in FIGURE 5, the zipped OASIS layout had 6% smaller file sizes when compared to the recommended OASIS layout. However, DRC loading times increased by an average of over 60% to offset this benefit, and, in several cases, the loading time more than doubled.
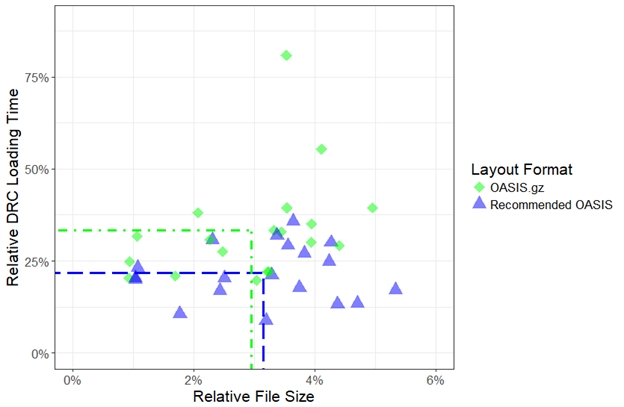
FIGURE 5. DRC loading time versus file size, both relative to the uncompressed GDS layout (smaller is better for both axes), with the means of both axes overlaid. There is a small file size reduction when zipping the uncompressed OASIS layout, but there is a significant loading time penalty.
What should I do next?
At 16 nm and smaller nodes, block-level and full-chip layouts should be in the OASIS format, specifically with the strict mode and CBLOCKs options enabled. Moving flows to utilize these recommendations can provide dramatically smaller file sizes and faster loading times.
Maintaining data integrity is critical, so layout designers may want to first switch a previous project to the OASIS format to reduce the risk and see firsthand the benefits of switching. They can also run an XOR function to convince themselves that no data is lost by switching to the OASIS format. Additionally, every time physical verification is run on an OASIS layout, it is another check that the layout is correct.
Layout designers can convert their layouts to the OASIS format using industry-standard layout viewers and editors. For best results, designers should enable both CBLOCKs and strict mode when exporting the layout. Designers should also confirm that these features are utilized in their chip assembly flow to reduce the loading time when running full-chip physical verification using their DRC tool.
Conclusion
File size and layout loading time have become increasingly important concerns as process technology advances. While storage is relatively inexpensive, it is an unnecessary and avoidable cost. Longer layout loading times encountered throughout the design process are similarly preventable.
The OASIS format has been around for almost 15 years, is accepted by every major foundry, and is supported by all industry-standard EDA tools. Switching to the OASIS format and utilizing features such as CBLOCKs and strict mode can provide users with dramatically smaller file sizes and faster loading times, with no loss of data integrity.
DENNIS JOSEPH is a Technical Marketing Engineer supporting Calibre Interfaces in the Design-to-Silicon division of Mentor, a Siemens Business. [email protected].
Editor’s Note: This article originally appeared in the October 2018 issue of Solid State Technology.








 Joe Kwan is the Product Marketing Manager for Calibre LFD and DFM Services at Mentor Graphics. He is also responsible for the management of Mentor’s Foundry Programs. He previously worked at VLSI Technology, COMPASS Design Automation, and Virtual Silicon. Joe received a BA in Computer Science from the University of California Berkeley and an MS in Electrical Engineering from Stanford University.
Joe Kwan is the Product Marketing Manager for Calibre LFD and DFM Services at Mentor Graphics. He is also responsible for the management of Mentor’s Foundry Programs. He previously worked at VLSI Technology, COMPASS Design Automation, and Virtual Silicon. Joe received a BA in Computer Science from the University of California Berkeley and an MS in Electrical Engineering from Stanford University.




