A week after Intel were claiming that their 14nm process will be ready to go at the end of next year, GLOBALFOUNDRIES (GF)
announced that they will have a 14nm finFET process for launch in 2014. Unfortunately they timed it to coincide with the iPhone 5, so we at Chipworks were tied up for a few days
tearing it down.
However, I don’t want to ignore this development — it could make the 2014 an interesting year! GF have dubbed the new process 14XM, for "eXtreme Mobility," since from the start it has been targeted on mobile applications — after all, mobile products are the volume driver in the chip business these days.
And what’s the biggest complaint from mobile users? Having to charge them so often, as battery technology has not improved at anything like a rate comparable to chip performance.
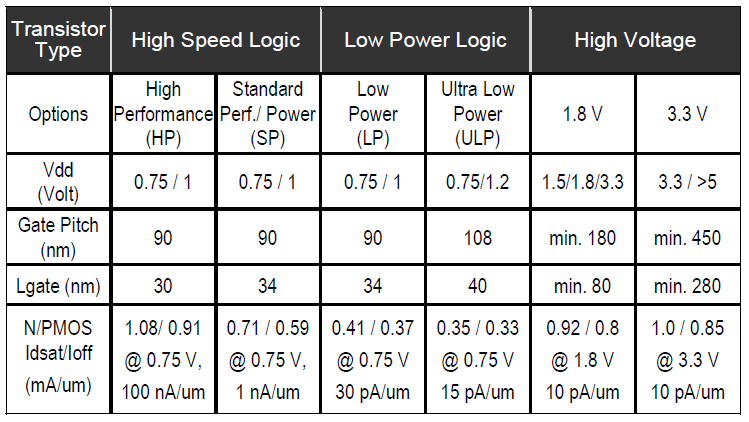
So while GloFo got started in high-k metal-gate (HKMG) making 32nm parts for AMD, they have seen the obvious and are generating low-power processes, beginning with the 28-SLP, moving to the 20-LPM, and now the 14XM.
The 20-LPM process claims a 40% reduction in power from the 28nm generation, and the 14XM claims 40%-60% increased battery life over 20-LPM. The 20nm generation is scheduled for next year, and as noted earlier 14XM is due out in 2014, a year later, breaking the two-year cadence that we’ve all got used to. Apparently 20nm wafers are running the full process in the Malta, NY fab right now.
They’re accelerating the process launch by using the 20-LPM middle/back end-of-line metal stack with the finFET front end. In the 20nm process the 1x metal pitch is 64nm and the single-patterned metal is 80nm — coincidentally, the latter is the same as Intel’s tightest pitch in their 22nm product.
 |
| 20nm metal pitches shown at the 2012 Common Platform Tech Forum (CPFT) |
The use of the 3D finFET structure enables a higher performance/unit area, or lower power/unit area at a given performance at the transistor level. The graph below shows some estimates made by their R&D group.
 |
| SoC Performance vs. power — lower power at constant frequency [1] |
Functional scaling itself will be limited to some extent by the 20-LPM metal density, but presumably some die shrink can be achieved by using more metal layers, and also the increased current density will allow some compaction since higher-current transistors will be smaller. Keeping single patterning will mitigate the cost, compared with double patterning for denser layers.
The process will also continue from the 20-LPM process in that it will use gate-last (replacement metal gate) technology on a bulk substrate. The R&D group in New York has published a couple of papers [2, 3] referencing a 40nm fin pitch, but 14XM will have a fin pitch of 48nm to leave some slack in the lithographic challenge, and minimize quantization errors. Together with the metal pitches of 64 and 80nm, it implies a 16nm grid as a basis for layout. The use of 64nm Metal 1 presumably also means that the contacted gate (CG) pitch will be 64nm.
The Intel 22nm process has a fin pitch of 60nm, and a CG pitch of 90nm, so it’s not unreasonable to assume that their 14nm process will have similar numbers.
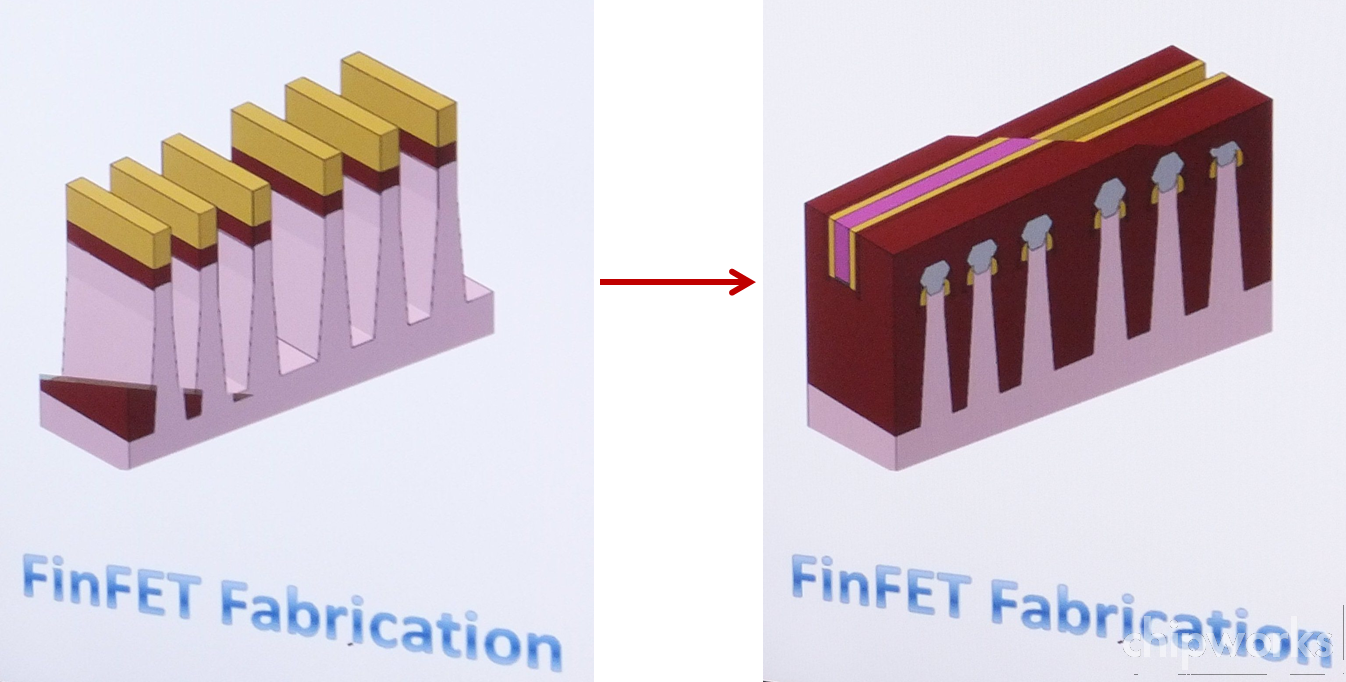
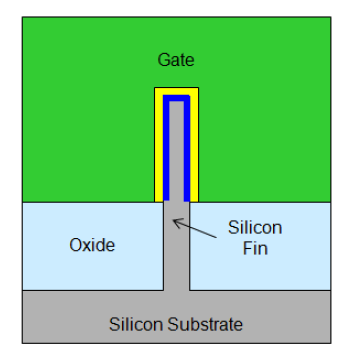
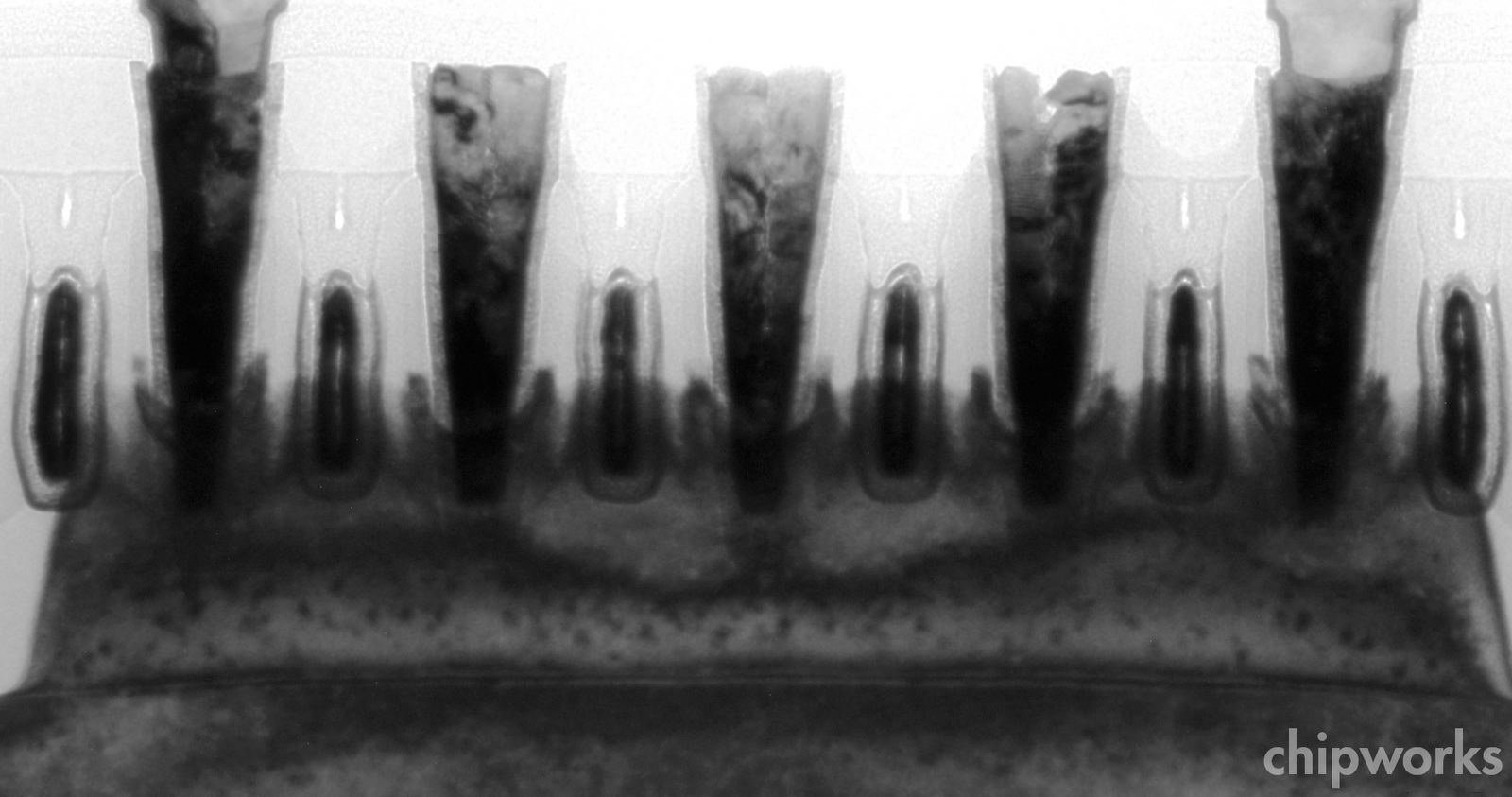
We will see whether the fin will be tapered similar to Intel’s; these images (below) from CPTF seem to show a vertical fin atop the STI profile, but then, they are only schematics. Using a single (STI) etch to shape the fins (as I think Intel does) should certainly be less complex than trying to get vertical-walled fins on top of the STI trench sidewall.
The economic challenge in going to 14nm is almost as huge as the technical challenge, and keeping the cost/power/performance (CPP) metric in check as process complexity spirals upwards has caused inevitable concern. In particular, the cost benefits of shrinking die size tends to go away as the lithography demands double, triple, and even quadruple patterning.
Jen-Hsun Huang of Nvidia has publicized his concern about increasing wafer costs at last year’s IPTC (International Trade Partner Conference) meeting — the plot below shows the increasing gap in wafer cost between successive nodes:
So if GLOBALFOUNDRIES, or any other foundry, wants to keep the customers coming, they have to mitigate the cost increase going to the next node. Taking a hybrid approach such as the 14XM process should be an attractive option for their existing and future customers.
It’s interesting to note that TSMC has changed tack slightly and are now saying that they will be using finFETs at 16nm, not 14nm. They are also claiming that their 20nm metal pitch is leading-edge at 64nm, although that’s the same as GF’s. It’s tempting to wonder if TSMC will also use a hybrid approach and transfer their 20nm back-end to the 16nm node, since the arguments are the same. Chenming Hu thinks so, anyway. TSMC are predicting 16nm risk production in 2014.
We’ll see if GF can match Intel’s timing — Mark Bohr sounded very confident at the Intel Developer Forum, when he said their 14nm product would be ready for the tail end of next year. Will we have GF-produced finFETs in early 2014? And will their finFETs be better than Intel’s?
My thanks to Subi Kengeri for clearing up some of the technical details.
[1] A. Keshavarzi et al., Architecting Advanced Technologies for 14nm and Beyond with 3D FinFET Transistors for the Future SoC Applications, Proc. IEDM 2012, pp. 67-70.
[2] T. Yamashita et al., Sub-25nm FinFET with Advanced Fin Formation and Short Channel Effect Engineering, Proc. VLSI 2011, pp. 14-15.
[3] C.-H. Lin et al., Channel Doping Impact on FinFETs for 22nm and Beyond, Proc. VLSI 2012, pp. 15-16.