Next Sunday the great and the good of the electron device world will be gathering in San Francisco for the 2010
IEEE International Electron Devices Meeting. To quote the conference web front page, “IEDM has been the world’s main forum for reporting breakthroughs in technology, design, manufacturing, physics and the modeling of semiconductors and other electronic devices.”
From my perspective at Chipworks, focused on chips that have made it to production, it’s the conference where companies strut their technology, and post some of the research that may make it into real product in the next few years.

In the last few days I’ve gone through the
advance program, and here’s my pick of what I want to try and get to, in more or less chronological order. As usual there are overlapping sessions with interesting papers in parallel slots, but we’ll take the decision as to which to attend on the conference floor.
On Sunday December 5th, we start with the short courses, “15nm CMOS Technology” and “Reliability and Yield of Advanced Integrated Technologies”. Kelin Kuhn of Intel has organised the former, and we have some impressive speakers – Thomas Skotnicki (ST – Trends and Scaling), Mukesh Khare (IBM – Device Challenges), Sam Sivakumar (Intel – Lithography), Yoshihiro Hayashi (Renesas – BEOL), and Clive Bittlestone (TI – Device/Circuit Interactions).
Having started in the business on 10-micron geometries, 15-nm devices seem crazy to me, but on the Intel clock it’s only three years away! I’m starting to tell folks to think about the end of silicon, at least as we know it, since my brain will not wrap around the idea of 11- and 8-nm gates, and 11-nm is only five years away (and 30 – 40 atoms across, depending on orientation!). The guys in the R&D labs have been thinking about that for the last decade or so (as we’ve seen at IEDM), so this should be an interesting day to see what they’ve come up with and how we get there.

The other side of the technology coin is reliability at these advanced nodes, and IMEC’s Guido Groeseneken has set up the other short course, with a slightly more academic slate of instructors. We have Ben Kaczer (IMEC – FEOL), Shinichi Ogawa (NIAIST – BEOL), Christian Russ (Infineon – ESD), Ashraf Alam (Purdue – Reliability-Aware Design), and Andrez Strojwas (PDF Solutions – Yield, Yield models, and DFM). Another good day – although the courses make a long Sunday, from 9 a.m. to 5.30 p.m., it’s worth sticking around to the end.
Monday morning we have the plenary session; a couple of good ones here, kicking off with Kinam Kim of Samsung, discussing silicon’s future (will it get beyond 11 nm?) and Arunjai Mittal of Infineon will discuss potential energy savings through the use of semiconductors – energy efficiency is one of the major themes of the conference this year. The third plenary is on bionanoscience in healthcare, a whole new area to me; the plenaries traditionally make the link between semiconductors and other fields of science.

After lunch we get to the conference proper. Straight into session 2, we have a set of 3D integration papers, by TSMC (paper 2.1), on integration at 28 nm, TSV-induced stress on HKMG (high-k, metal-gate) devices by Panasonic/Qualcomm/Samsung/IMEC/Newcastle U (2.2), and IBM (tungsten TSVs – 2.4), and some more academic institutions.
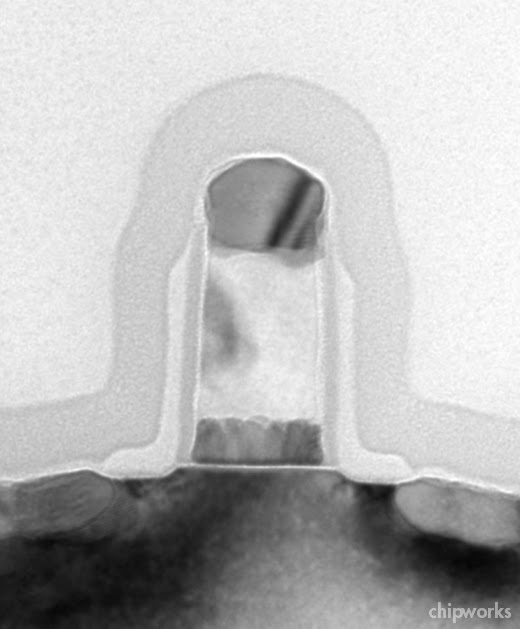
Session 5 on memory technology is split between traditional floating gate flash papers by Samsung (5.1) and Intel/Micron (5.2), and charge-trapping MONOS/SONOS flash, with two papers by Macronix (5.5, 5.6). Micron and Samsung are touting their 25 and 27-nm (respectively) NAND flash technologies; Micron has solved the interline capacitance (wordline/wordline and bitline/bitline) problem by using airgaps:


 |
| Micron 25-nm NAND Flash – X-Sections of Wordlines and Select Transistors (top) and Bitlines (bottom) Source: Micron/IEDM |
To my knowledge this will be the first volume production of air-gap technology in any product, even though there have been announcements by IBM and others discussing its use in the metal-dielectric stack. It’s kind of ironic that this is in the process front end! Laura Peters has been previewing a number of IEDM papers at ElectroIQ, and more details of this one can be found here. We’ll see how Samsung gets around the same problemâ??¦
There’s also a paper from NCSU (5.3) discussing TaN floating gates down to 1 nm thick; if it works it will be a step towards vertically shrinking the NAND flash stack, something that hasn’t happened much so far in the conventional two-polySi gate structure.
Intel have a couple of papers (6.1, 6.7) indicating where they may go at the 15- and 11-nm generations; both detailing Quantum-Well Field Effect Transistors (QWFETs), the former InGaAs finFETs, and the latter strained germanium pFETs.
Come 6.30 there’s the reception, a chance to see folks we haven’t seen since the last year, or at least since Semicon West, the last tech-fest I was able to get to. Bring ear-plugs – a thousand-plus engineers talking at the same time make a lot of noise!
Tuesday morning there’s a session on high-k and channel engineering, with the IBM Alliance tuning pFET VTH with a Ge implant (11.4, Laura’s take here), and TSMC/Nanyang U discussing gate stack annealing in their gate-last process (11.6, Laura)
Session 12 features another group of memory papers; Hynix is giving an invited review paper (12.4), and is co-affiliate with Grandis on a spin-torque RAM (12.7); and IBM (12.5) and Samsung (12.6) have papers on the same topic.
Session 13 is a highlight session of invited papers on “Next Generation Power Devices and Technology”, covering the field from silicon and silicon carbide to gallium nitride devices.
In the field of image sensors, TSMC has an invited paper (14.1) on a 0.9 µm pixel BSI (backside illumination) image sensor and the scaling challenges involved. TSMC fabs the sensors for Omnivision, which are now at the 1.4 µm BSI generation commercially, so maybe we’ll see this one in a couple of years. Omnivision has now migrated to a 300-mm copper process for their 1.1 µm pixel part, just being launched. This is how we get 12-Mpixel cameras in a cell phone!

 |
| Cross-Section of Omnivision OV5642 1.4 µm-Pixel BSI Image Sensor |
The IEDM conference lunch speaker is Jim Clifford of Qualcomm, on the evolution of their chipsets and the technology required – we have just seen their first 45-nm part, and they are leaders in multichip packages; maybe we’ll get a hint of their 28/32 nm and TSV plans.
Macronix has a third paper (19.2) in the afternoon memory session on tungsten oxide resistive memory; and in the power session Panasonic (20.5) describes a high-voltage (1300+ V) AlGaN/GaN on silicon device, and TSMC talks high-performance LDMOS (20.8). In general the afternoon has a preponderance of academic speakers, with other sessions on device/circuit interactions, advanced processes, thin film transistors, memory simulation, and graphene (sessions 17, 18, and 21 – 23).
At 5.15 we have the first of three sponsored events; Applied Materials is holding a technical symposium, “Is Moore’s Law Taking Us in a New Direction? The Future of Transistor Technology”, around the corner at the Wyndham Parc 55 hotel, with a slate of speakers from GLOBALFOUNDRIES, IBM, Qualcomm, ST and other companies.
And if that’s not enough, there are the conference panel sessions back at the Hilton at 8 p.m. – “Heterogeneous Device Integration as Enabler of Functional Diversification for More than Moore”, which promises to range from nanomaterials to 3D chip stacking; and “Power Crunch – Threat or Opportunity?”, discussing power optimization at the transistor, circuit, and system level.
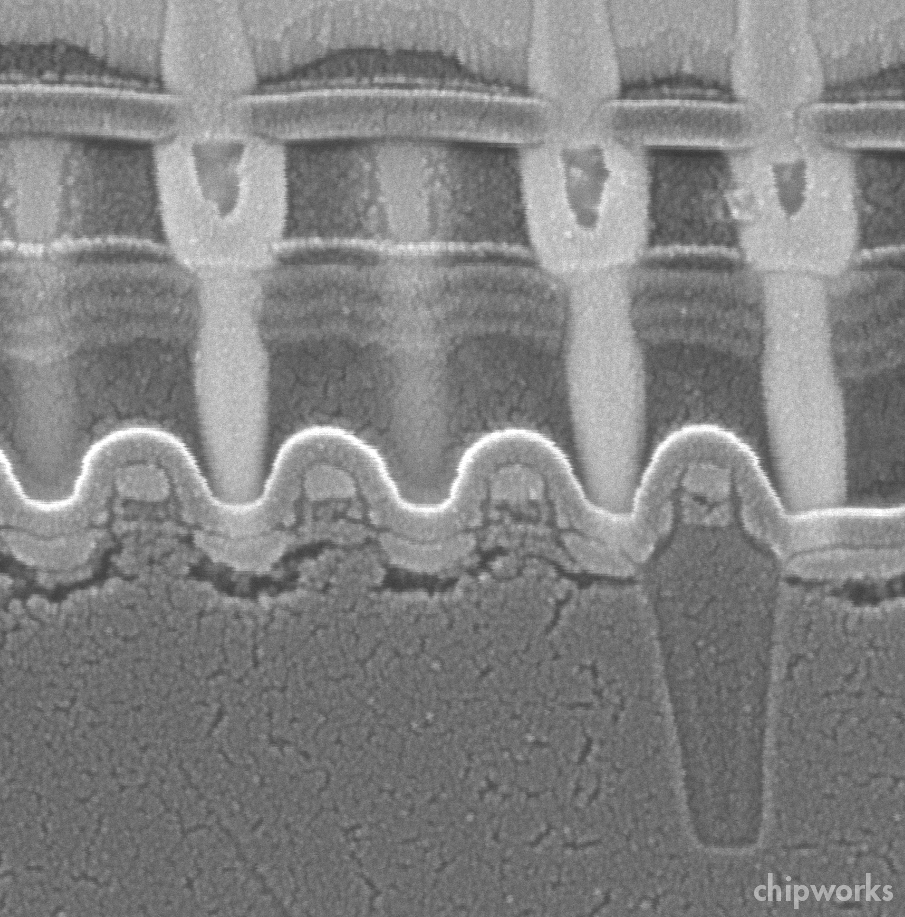
By the end of those (if I’ve lasted that long) I will surely be getting into information overload, so I hope I sleep well, ready for session 27 on Wednesday morning, which covers off the advanced HKMG CMOS papers.
TSMC are discussing 22-nm FinFET process (27.1), Intel (27.2) have a HKMG RFCMOS review, Qualcomm (27.3) are talking 28-nm low-power SoC technology (gate-first or gate-last – we’ll see!), and IBM (27.5) are updating the 32-nm eDRAM work they presented last year. The odd paper out (27.4) is a more theoretical study by Texas Instruments of the way 1/f noise is affected by layout features such as active/active spacing and dual stress liner boundaries.
 |
| Cross and Longitudinal (right) Sections of TSMC 22-nm FinFET (Source: TSMC/IEDM) |
In the parallel sessions Renesas is detailing microwave annealing of NiPt silicide (26.1), STMicroelectronics et al.(29.1) and NXP-TSMC (29.2) have phase-change memory papers, and Hynix (29.7) is showing off a 3D NAND-flash memory cell.
Lunchtime, ASM is holding their fourth annual seminar with their own speakers and Mike Chudzig from IBM, on ALD and epitaxy in CMOS.
Afternoon session 33 (novel processes) kicks off with an invited talk by Ichiro Mori of SELETE (33.1) on their EUV results; I’m not sure the concept of EUV is novel any more, but it’ll be interesting to see how far things have come.
Renesas has a paper on embedded DRAM with MIM capacitors in porous low-k (33.3), continuing the technology we have seen from the former NEC in the Nintendo Wii – now in volume production in their 55-nm process.
 |
| Embedded DRAM Capacitor Stack in NEC-Fabbed Memory Die From Nintendo Wii |

A little later there is a talk by the IBM consortium on 32 nm BEOL using copper with a copper/manganese seed layer (33.5), followed by TSMC (33.6) discussing chip/package interactions when extreme low-k dielectrics are used.
In parallel sessions, TSMC have another FinFET paper (34.1), and a breakdown study of low-k dielectrics (35.2). Toshiba have an interesting failure analysis study (35.3) looking at anomalous phosphorus diffusion by scanning spreading resistance imaging, followed by U. Cal, IMEC, and Infineon (35.4) examining the effect of strain on ESD protection devices. Laura P. adds detail at ElectroIQ
here.
By Wednesday afternoon a lot of attendees will be heading for home, and I’m usually thankful when the last paper’s done, but that’s not the end this year! The
SOI Industry Consortium is holding a
workshop on fully depleted SOI starting at 5 p.m., with some notable speakers from academe and industry. It will be in the Hilton, preceded by a reception and followed by a buffet supper to aid the weary bones and brain cells.
So as always, no peace for the curious! I will be trying to post a more detailed blog as the conference unfolds, but given all the interesting topics being covered, time may be at a premium. I hope to see you there!