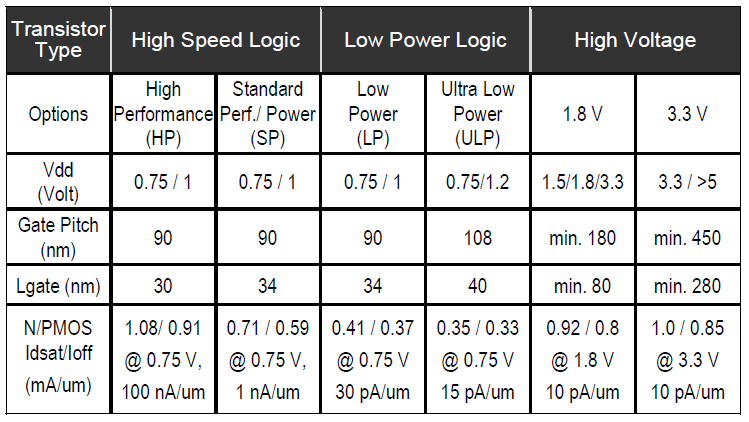
The first surprise was that this is a gate-first process, contrary to the announcements made by the Common Platform group that the 20nm class processes would be gate-last. The difference seems to be that this technology IS aimed at high performance servers and their support devices, not consumer products, and this is IBM’s process for its high-end products, so they are sticking with the proven formula and pushing it to the next level.
The gate dielectric stack has been scaled to reduce the inversion thickness (tinv) by 7%/10% (NMOS/PMOS), without affecting mobility, modifying the clean, depositions (using ALD for the interfacial oxide), and anneal steps to achieve the lowest tinv published so far, and reducing DIBL by 6%/8%.
The second surprise was that e-Si:C (embedded carbon-doped source/drains) has been used for NMOS stress — IBM claimed that this is the first time in a production process. I had just about written e-Si:C off as a viable manufacturing technique, since I’ve been hearing over the last few years that the carbon is not stable and does not stay in the substitutional crystalline sites where it’s needed. However, here we are told that it is stable and that it survives all the backend processing, even with the 15 layers of metal used in this technology.

The e-Si:C incorporates ~1.5% C, which combined with fourth-generation e-SiGe with more Ge and the dual-nitride stress liners, gives 25% more strain than the 32nm process.
The gate-first approach allows conventional contacts and self-aligned silicide, and judging by Fig. 3, raised source/drains help to reduce S/D resistance and keep the gate/contact capacitance under control.
The embedded trench DRAM is not a surprise, IBM has a long history in the field and they have now brought it to the point where access time is shorter than SRAM [2, 3, 4].

The big change here is that the substrate wafer has an N+ epi layer on it to replace the diffused cell plate of earlier generations. This allows denser packing, since a formerly-needed diffused spacer is removed, giving a cell size of 0.026 μm2. It also enables deeper trenches, giving higher cell capacitance for an areal capacitance of 280 fF/ μm2. The trench capacitors are also used as decoupling capacitors, and these are isolated by deep trench isolation so that they can be biased independently.

cross-section schematics of decoupling and isolation trenches, showing N+ epi plate [1]
(As an aside, one of the comments from Greg Taylor of Intel in his microprocessor talk in Sunday’s IEDM short course was that the analog functions that are part of a CPU are getting more significant as dimensions shrink. Both Intel and IBM are now using on-chip decoupling capacitors; Intel with MIMCAPs, and IBM with trench capacitors.)
The complexity of IBM’s server chips is reflected in the 15 levels of metal. The first level is doubled-masked with a litho-litho-etch sequence to allow for orthogonal layout; the rest are single-patterned using uni-directional layout. Self-aligned vias help with packing, and both ultralow-k and low-k dielectrics are used as needed.
IBM is prototyping 22nm server parts right now, but even when they get into the servers for sale, I likely won’t get my hands on one — a bit beyond my procurement budget!
[1] S. Narasimha, IEDM 2012 pp. 52-55
[2] S. Iyer, ASMC 2012
[3] N. Butt, et al., IEDM 2010 pp. 616-619
[4] J.Bart et al, IEEE Journal of Solid-State Circuit, Jan 2011