The International Electron Devices Meeting started its 56th session last week on Sunday in San Francisco. This year the program appears to more academic than in previous years, and this was confirmed by the conference chair in his opening address – only 145 submissions out of a total of 555, an all-time low as a percentage. Attendance was guesstimated at ~1500, again lower than earlier years on the west coast. On the other hand, the atmosphere is noticeably more upbeat than last year, and there are plenty of industry attendees.
Sunday was short course day, well attended with ~580 participants. There were two courses, “15nm CMOS Technology”, and “Reliability and Yield of Advanced Integrated Technologies” – I sat in on the reliability session and brought myself up to date on the issues now that we’re into the deep nanometer era. The European weather had its effects, the chair Guido Groeseneken was stuck in Amsterdam due to snow, and Werner Weber had to take over. So far Europe has had a worse winter than I’ve had to cope with in Canada!
The course had some useful stuff for me, not being involved in reliability – it’s not something we need to worry about when we take stuff apart! We had a good review of time-dependent breakdown and n- and p-BTI by Ben Kaczer of IMEC; some interesting new analytical work on changes in low-k dielectrics from Shinichi Ogawa; a surprisingly optimistic review of ESD techniques by Christian Russ of Infineon (apparently strain can actually improve ESD performance!); and the day was rounded out by consecutive reviews of different approaches to reliability by design mitigation by Ashraf Alam (Purdue) and Andrzej Strojwas (PDF Solutions).
On the 15-nm course, the gossip I heard was that folks were pleasantly surprised that there is a roadmap to get there. Tom Skotnicki convinced people that the thin SOI/thin BOX solution will work better than finFETs – at least he didn’t get snowed in!
Monday morning we got into the plenary session, starting with Kinam Kim of Samsung. He started off by predicting that DRAM will get into the 10-nm generation, though not for another ten years, by using new variants of MIM stacked capacitors, and evolving through buried wordlines to vertical access transistors with buried bitlines.
Then he moved on to flash, detailing the problems created by a shrinking number of electrons on the floating gate, the increasing aspect ratio of the gate stack, and the inability to scale the dielectrics. We’ll still get to the 1x node, but after that 3D cell structures will appear, likely with charge-trapping technology. We had a brief reference to ReRAM as universal memory (though as the Scots say, I ha’e ma doots), but it’ll be a while before we get there.
Then we moved into logic, with the many variants possible below 20-nm – finFETs, hybrid chips with III-V devices on silicon, graphene, etc, and a quick run-through of the various stacking options such as package-on-package and (of course) TSVs; the latter was apt in the context of the day’s announcement of an 8-GB DIMM using TSVs.
The second plenary talk was equally interesting in pointing up the actual and potential use of semiconductors in making electrical consumption more efficient, from generation through transmission to end usage. Examples given were whole-wafer thyristors used for switching HVDC lines (apparently DC transmission is much more efficient than AC, and there’s a 1400-km, 800KV line in China), and at the other end of the scale a server power supply with 99% efficiency.
 |
| Schematic (top) and Image of Whole-Wafer Laser-Triggered Thyristor Switch (Source: Infineon/IEDM) |
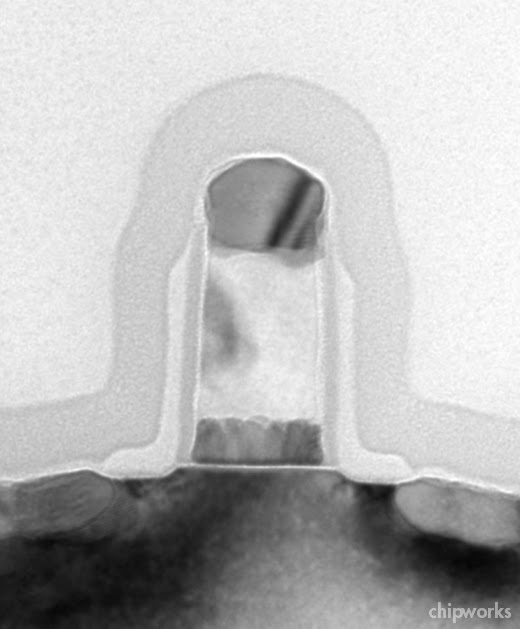
The afternoon memory session started off with Samsung’s 27-nm NAND flash paper (5.1). It amazes me every time that we see a new generation of NAND flash that the cell is essentially a shrink of the classic control gate/floating gate structure, even though we’re now counting electrons.
That’s what we have here:
 |
| Samsung 27-nm (left, source: Samsung/IEDM) and 35-nm NAND Flash Gate Structures |
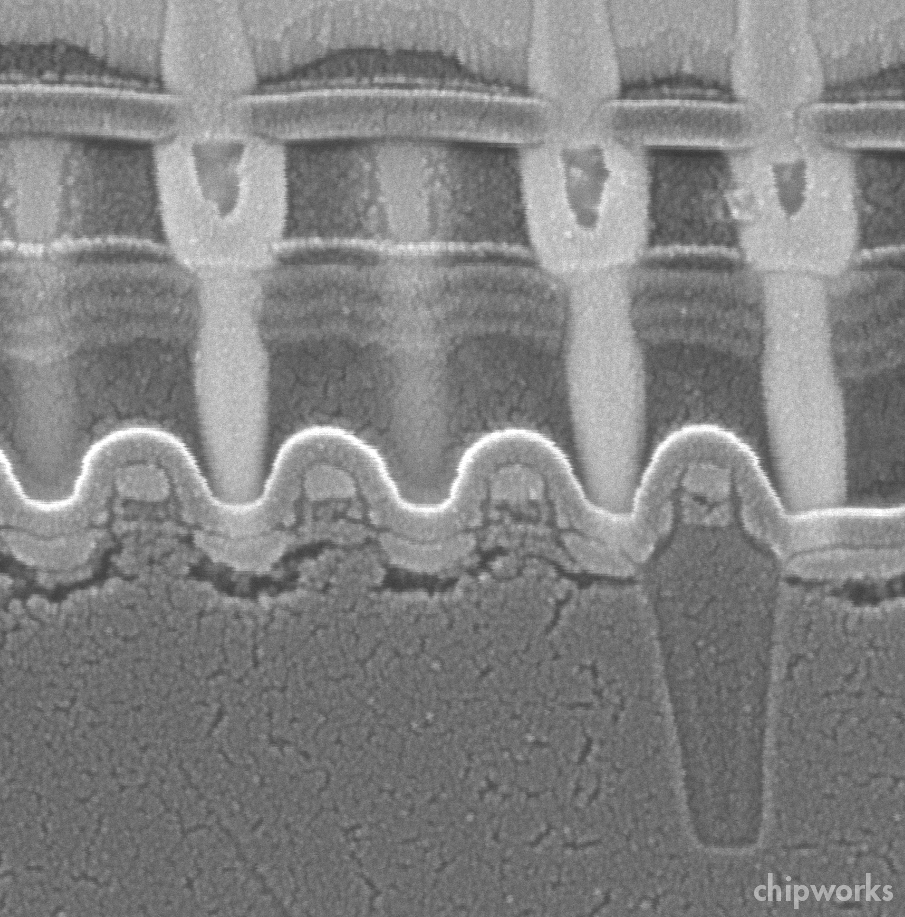
I’ve included an image of the 35-nm cell for comparison, to show the essentially similar structures, control gate/wordline (CG) on top, and floating gate (FG) below. Below is an orthogonal section along the line of the control gate, again with the 35-nm part for comparison.
,
 |
| Section Parallel to Control Gate of 27-nm (left, source: Samsung/IEDM) and 35-nm NAND Flash |
The main difference we can see, apart form the dimensional shrink, is the increase in the aspect ratio of both gates. This deliberate, to maintain the coupling ratio between the control gate and floating gate, and also the resistivity of the wordline to minimize RC delay (8 ohm/sq is quoted).
One of the changes discussed in the paper is a novel tunnel oxidation process (i.e. between FG and substrate) that conserves the boron doping in the channel and raises the Vt by ~0.5V. This tweak is useful for a number of performance considerations:
- the reduced Vt shift between a programmed state and an un-programmed state helps reduce the capacitance linkage between adjacent floating gates
- it improves endurance by reducing the fringing field between the top corner of the active silicon and the control gate, where it comes down close to the substrate between floating gates – during programming the high voltage across this gap can cause tunneling to the CG, which can degrade the tunnel oxide and affect endurance.
- it improves the data retention by reducing charge leakage off the floating gate
This “novel tunnel oxidation” is not described in detail, but if we blow up their somewhat fuzzy TEM image, and compare again with the 35-nm chip, it looks as though the tunnel oxide has been nitrided.

 |
| Tunnel Dielectrics of 27-nm (left, source: Samsung/IEDM) and 35-nm NAND Flash |

A question was asked at the end of the paper about the novel oxidation, and of course the presenter didn’t give a direct answer, but an implant step was mentioned; a locking implant for the boron seems likely.
I’ve gone into more detail about this paper than is probably sensible in a blog, but it was the first paper of the regular sessions, and the detail of getting 64Gb of cells that work onto one die can’t help being fascinating to a process geek like me.
Next up (5.2) was Micron’s 25-nm flash, which they announced almost a year ago. A different take on the same challenges, Micron have used air-gap technology to mitigate the capacitance linkage between adjacent gates, and adacent bitlines (see below).
 |
| "Air Gaps" in Micron 25-nm NAND Flash (Source: Micron/IEDM) |
Essentially they seem to have optimized the uneven fill that we have often see in similar structures (e.g. the Samsung part above), and of course “air-gap” is a bit of a misnomer – I presume it’s actually a vacuum with whtever trace gases are in the deposition chamber when the dielectric is formed.
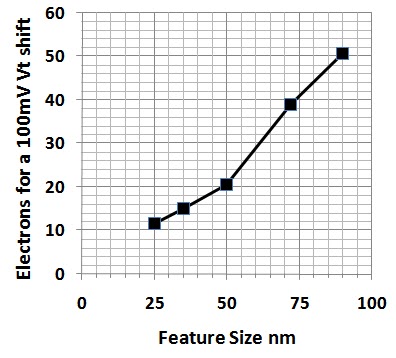
They also illustrated that at the 25-nm node, we’re down to about ten electrons on the floating gate for a 100 mV Vt shift, so in a typical MLC cell with 300 – 500 mV separation between levels, that’s about 30 – 50 electrons difference. With this degree of sensitivity, any traps in the stack can affect the Vt, so considerable effort has been taken to minimize trapping and charge leakage.
 |
Electrons required for a 100mV Vt shift vs. cell feature size.
(Source: Micron/IEDM) |
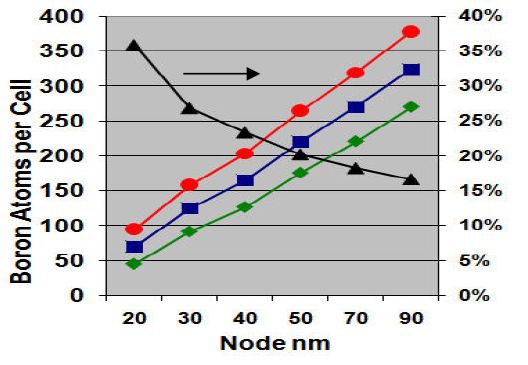
Micron also highlighted the sensitivity to boron concentration in the channel – instead of counting electrons, we’re counting atoms – at 25 nm we’re down to ~75 atoms, with a 3Ï?? variation of ~35%, and a corresponding effect on Vt; together with the increased sensitivity to noise at this node, some serious work has had to be done on the programming algorithms and error correction.

 |
Number of Boron atoms per cell vs. feature size.
(Squares – mean; diamond – -3Ï??; circle – +3Ï??; triangles – ±3Ï?? percentage divided by the mean. Source: Micron/IEDM) |
Later in the afternoon Macronix had a couple of papers (5.5, 5.6) on the other flash technology, charge trapping (CT) using a nitride layer. Macronix has been one of the more prolific industrial contributors in recent years, with six papers this year and seven last year.
Coincidentally, the first paper is on a BE-SONOS NAND flash structure (barrier-engineered SONOS), which uses a thin ONO layer under the charge-trapping nitride layer, instead of under the floating gate (as we speculate above, in the Samsung paper). The thin ONO layer is used as a “modulated tunneling barrier”, which suppresses hole tunneling at low electric fields for retention, but allows efficient tunneling at high fields for erase.
That gives us a ONONO stack under the gate;
 |
Orthogonal Sections of Macronix 38-nm BE-SONOS NAND Flash
(Source: Macronix/IEDM) |
The detail in the paper reveals that the lower two oxides are actually nitrided, and the ONO barrier layer thicknesses are 13/20/35 Å (bottom – top), covered by a ~70 Å nitride layer and another ~70 Å oxide, formed by oxidizing the nitride layer. 75-nm and 38-nm NAND flash structures were tested.
The intent of this work is to show that the reliability is improved by leaving the dielectric stack intact, as opposed to etching it when the gates are etched; previously it had been thought that the CT layer had to be etched to stop charge spreading on the nitride. In this they seem to have succeeded, since there is no change after a multiplicity of cycling tests, too many to go into detail here. The results indicate that there is no lateral charge spreading on the nitride CT layer.
Since the CT dielectrics do not need to be cut, this avoids any in-process damage at the edge of the dielectric; an advantage over the cut-dielectric version of CT-flash, but also over floating-gate flash, since these days the floating gate and STI are defined simultaneously, and the FG edge and tunnel dielectric are vulnerable.
The other Macronix paper (5.6) details a study of fast initial charge loss in CT-flash devices, incuding BE-SONOS, where the Vt shifts within a second of programming, and then saturates at a stable value. They minimised this by optimizing the film stack, and by refill programming to duplicate program levels.
Macronix has done a lot of work on the different CT-flash technologies, but BE-SONOS seems to be particularly pragmatic form, and a viable alternative to FG-flash – will we see it in production any time soon?
That was the end of day 1 of the conference; there were other papers that I missed, but I will be trying to review them in the next few weeks; meanwhile part 2 of IEDM retrospective will be up in a few days, covering the final two days of the meeting.